基于强化学习的区域防空反导决策仿真探讨
本文是一篇决策模拟论文,本研究用于解决区域防空反导作战中决策智能化的问题,提高了预测准确率和拦截命中率;同时,研究还探索了强化学习在兵棋推演中的新应用,推动了军事领域的智能化发展;因此,本研究对提高反导作战效率和推进军事技术的发展具有重要意义。
第一章 绪论
1.1 研究背景及意义
随着世界各国军事实力的发展,空袭武器也处于快速的变革中,具有远距离、高精度打击能力的导弹成为现役轰炸机重点携带的武器,而打击距离远、杀伤能力强、范围广的弹道导弹已经成为现代化战争中最具有威胁性的武器之一,引起了世界各国的密切关注。针对这种新型的导弹攻防背景,各国都在大力研究导弹防御问题并研制相关系统,因此区域防空反导成为一项极其重要的军事任务,世界上主要的军事强国都在大力研究导弹防御问题并研制相关系统,防空反导的能力强弱也成为现代化战争中衡量军事水平的重要标准之一。
在区域防空反导决策中,智能指挥系统需要快速理解态势、决策战斗行动、优化武器控制等,这些需要在不完整、不确定和不可预见的战场环境下进行,因此智能指挥系统需要实现高效、准确的决策能力,即需要更加智能化的解决方案[1]。随着人工智能的发展,强化学习作为一种新兴的人工智能技术,为区域防空反导决策智能化提供了新的研究方向。
强化学习技术能够对环境进行建模和学习,通过智能体与环境交互来优化行为决策,从而实现多智能体系统协同决策、数据驱动的策略优化等,有望为区域防空反导作战提供更高效、精准的指挥决策支持。在区域防空反导中,强化学习可以被应用于多个环节,例如针对空中目标的态势预测、火控指挥和武器控制等。通过强化学习智能体的迭代训练和优化,可以使得防空反导系统更加智能、自适应和高效。在防空反导领域,强化学习已经被广泛应用于智能指挥、武器控制、态势理解等方面,并取得了一些令人瞩目的成果。
...........................
1.2 国内外研究现状
1.2.1 强化学习研究现状
强化学习是机器学习领域的一个分支,主要研究如何通过智能体与环境的交互,使得智能体可以在环境中自主学习并不断优化策略,从而最大化累计回报。强化学习算法主要基于值迭代、策略迭代、蒙特卡罗方法、时序差分法等[7]方法构建。其中,Q-learning算法是一种基于值迭代的强化学习算法,它通过构建一个Q-table来记录每个状态和动作的奖励值,从而实现最优策略的学习[8]。Deep Q-Network(DQN)算法是Q-learning算法的扩展,它通过使用深度神经网络来逼近Q-value函数,解决了Q-learning算法中状态-动作空间过大的问题[9]。Policy Gradient算法则是一种基于策略迭代的强化学习算法,它直接学习策略函数,不需要构建值函数,具有更好的收敛性[10]。Actor-Critic算法则是一种融合值迭代和策略迭代的算法,它同时学习值函数和策略函数,具有更好的效果和稳定性[11]。
强化学习在游戏智能领域的应用较为广泛,如AlphaGo[12]等基于强化学习的围棋程序,以及OpenAI Five等基于强化学习的游戏AI[13]。在自主驾驶领域,强化学习可以用于实现智能体的路径规划、车辆控制[14]等任务,如深度强化学习在无人驾驶中的应用[15]。在机器人控制领域,强化学习可以用于机器人的运动控制[16]、物品抓取[17]等任务,如机器人在复杂环境下的路径规划[18]。
在军事领域,强化学习可以应用于许多不同的场景中,包括以下几个方面:
(1)自动化作战系统:强化学习可以帮助军队设计和实现自动化的作战系统。通过自主学习和优化,这些系统可以自动执行一些任务,例如:文献[19]提出了一种基于灰狼优化算法和强化学习的算法,该可以使无人机能够根据累积的性能自适应的切换操作,包括探索、开发、几何调整和最优调整;文献[20]提出Hector算法,能最大限度地减少军用无人机群的伤亡。
(2)战术决策支持:强化学习可以帮助军队在战术决策中做出更加准确地判断。例如:文献[21]采用深度强化学习和兵棋推演技术构建了一个作战决策系统,用来帮助指挥官在复杂环境中快速做出决策;文献[22]提出深度神经网络作为函数逼近器,并将其与Q-learning相结合进行了仿真,为无人作战飞行器(UCAV)的空战决策研究提供了一种新思路。
(3)智能武器系统:强化学习可以帮助设计和实现智能武器系统。例如:文献[23]通过深度强化学习,提出了一种兼顾制导精度和突防能力的机动突防制导策略。
...........................
第二章 强化学习算法及主要模型
2.1 强化学习算法
本文对区域防空反导决策的研究主要是基于强化学习进行开展,在本章中将详细介绍强化学习算法。
2.1.1 强化学习简介
强化学习(Reinforcement learning, RL)机器学习中的重要分支,主要是用来解决序贯决策(sequential decision making)任务,即连续决策问题,例如博弈游戏、军事作战、机器人控制等需要连续决策的任务。强化学习是在机器与环境交互过程中通过不断的学习策略、做出决策来达到回报最大化或指定目标的算法。
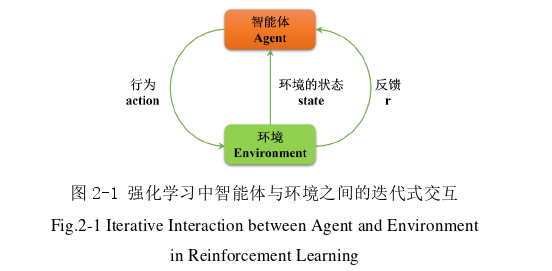
强化学习的主要目的是让智能体在不断地与环境交互中学习如何做出最优的决策。为了实现这一目标,强化学习通常遵循马尔可夫决策过程(Markov decision process,MDP)模型,交互模型如图2-1所示:
决策模拟论文怎么写
由图2-1可知,在强化学习的交互过程中,智能体会根据当前状态以及策略选择一个动作,并将其应用于环境中。环境会返回一个即时奖励信号以及下一个状态。智能体通过观察这些信息来更新自己的策略,并继续与环境交互。在交互的过程中,智能体会逐渐学习到如何做出最优的决策以最大化未来的奖励总和。
........................
2.2 主要算法模型
在本文中,主要使用的强化学习算法分别是SAC、PPO、MBPO和MADDPG,追踪预测算法模型和协同拦截算法模型将基于这些算法构建,并为区域防空反导决策提供新的解决方案。
2.2.1 SAC算法模型
SAC(Soft Actor-Critic,SAC)算法是一种基于最大熵的强化学习算法,用于解决连续控制问题,例如机器人控制和游戏控制等问题。该算法采用的是Off-Policy算法,可以在离线数据上进行训练,同时也支持在线学习。
SAC算法主要由策略网络、Q网络和值函数网络三部分组成。策略网络是用来产生动作的概率密度函数的神经网络。SAC算法采用的是高斯策略函数,即策略函数是由高斯分布给出的,其均值和方差由策略网络的输出确定。策略网络的损失函数包括策略函数的熵和Q值的负值,其目标是最大化策略函数的熵以增加探索性能,同时最小化Q值以保证策略函数的有效性。
SAC算法的训练过程包括两个步骤:首先使用策略网络进行采样,并使用双Q网络更新Q值和值函数网络,然后使用策略网络和值函数网络更新策略。这样可以保证策略网络在采样过程中尽可能地探索环境,并在更新策略时最大化策略函数的熵以增加探索性能。SAC算法也支持离线训练,即使用离线数据来更新Q值和值函数网络,而不需要与环境进行交互。在SAC算法中,有几个重要的超参数需要设置,包括策略函数的熵权重α、两个Q网络的更新权重、目标网络的更新权重等。这些超参数的设置会影响算法的性能和收敛速度。通常需要进行实验来找到最优的超参数设置。
总之,SAC算法是一种适用于连续控制问题的强化学习算法,具有离线训练和在线学习的能力,能够在探索性能和效率之间找到平衡点,已经在机器人控制和游戏控制等领域取得了良好的效果。
..........................
第三章 区域防空反导战场模型 ....................... 25
3.1 区域防空反导战场建模理论 ............................ 25
3.1.1 区域防空反导战场建模环境 ................... 25
3.1.2 区域防空反导战场建模特点 ......................... 27
第四章 区域防空反导追踪预测模型 ................. 37
4.1 追踪预测模型分析 .................. 37
4.1.1 异构更新方法 .................................. 37
4.2 追踪预测模型设计 ................................ 38
第五章 区域防空反导协同拦截模型 ............................... 58
5.1 协同拦截模型分析 ................................. 58
5.2 协同拦截模型设计 ............................... 59
第五章 区域防空反导协同拦截模型
5.1 协同拦截模型分析
协同拦截模型主要作用是拦截攻击自身或编队的来袭导弹。在拦截模型中主要解决的问题有:(1)哪艘舰船进行拦截、(2)使用什么导弹拦截、(3)什么时候拦截来袭导弹、(4)在一次拦截中使用几枚导弹、(5)对于一枚来袭导弹拦截几次。
对于问题(1)以看作编队内舰船协同问题,本文通过将一个编队抽象成一个智能体和一艘舰船抽象成一个智能体两种方式进行。前一种方式,是通过智能体对编队做出中体决策,来解决编队内舰船协作问题;后一种方式通过使用一个中心化的评价网络训练多智能体。
对于问题(2)可以看作单智能体的决策问题。由于在同一艘舰船内的防空导弹的射程不同,所以本文针对这个问题,将不再设置深度强化学习智能体,而是通过使用规则直接设定防空导弹的使用方式。具体使用方式如表 5-1所示。

决策模拟论文参考
..........................
结论
针对区域防空反导决策如何智能化的问题,在本文中探讨了如何使用强化学习来优化反导决策策略,本文的主要内容与创新点如下:
(1)为了解决防空反导作战的复杂和随机性,在本文中,我们结合OODA循环作战理论构建了防空导弹作战流程。该流程将反导决策问题分解为追踪预测和协同拦截两个模型。在追踪预测模型中,主要解决来袭导弹是否攻击舰船以及攻击哪艘舰船的问题;而在协同拦截模型中,则主要解决编队中是否进行拦截、哪艘舰船进行拦截以及发射几枚导弹进行拦截的问题。
(2)为了解决推演时间过长和推演过程中的无效数据问题,本文结合马尔科夫决策过程,提出了一种异构更新方法。该方法设定一个判定区域,将来袭导弹进入判定区域视作马尔可夫决策过程的开始,而将来袭导弹消失或离开判定区域视作该过程的结束。在追踪预测模型中,将判定区域设置为东经124°到东经126.5°;而在协同拦截模型中,则将判定区域设置为编队以核心舰为中心的射程范围。这样可以有效提高推演效率并减少无效数据的干扰。
(3)在追踪预测算法模型的构建中,构建了SAC追踪预测算法、ISAC追踪预测算法、IPPO追踪预测算法和MBPO追踪预测算法模型,并为它们设计了相应的动作空间、状态空间和奖励函数。在仿真训练中,设定了一些限制和规则,如禁止红方舰船开火、启用自动规避等,来模拟实际作战情境。最终,对几种算法结果进行了分析,发现MBPO追踪预测算法具有更高的收敛稳定性和预测准确率。
参考文献(略)
- 民机乘客应急疏散决策仿真优化思考2023-12-03
- 面向节水的工业企业生产用水决策模拟及调控政策优...2024-03-26

