我国参与中高风险金融资产投资的家庭识别及其影响因素分
本文是一篇投资分析论文,本文发现Logistic模型与随机森林模型对于金融领域的客户识别方面的应用有比较优良的表现,更适合作为识别我国参与中高风险金融资产投资的家庭的模型,该方法可以在现实中的金融机构进行客户开发,以帮助金融机构应对大数据时代的挑战。
1 绪论
1.1 选题背景与研究意义
1.1.1 选题背景
家庭是社会和经济活动的基础单元,而家庭参与投资的活跃程度更是国家经济发展水平的重要衡量指标。2021年10月欧洲安联集团发布的《2021年安联全球财富报告》①对全球多个主要经济体家庭资产负债的调研显示,疫情并没有对全球财富产生冲击性的影响,2020年全球金融资产总额相较去年仍然增长了近10%,首度超过了200万亿欧元(约合人民币1500万亿)。
而在中国,安联发布的报告显示,中国家庭金融资产总额在2019年与2020年连续两年的增速超过10%,增速远高于全球平均水平,2020年中国家庭金融资产总额超过2.5万亿欧元(约合人民币18.6万亿),占亚洲金融资产总额的47%。报告还显示,2020年中国家庭总净金融资产同比增长13.9%,人均净金融资产达到12430欧元(约合人民币92643元)。而在2009年,中国家庭人均净金融资产仅为3010欧元(约合人民币22434元),11年来增长超过300%。由此可见我国的家庭金融资产总额还处在上升时期。此外,西南财经大学中国家庭金融调查与研究中心和蚂蚁金服集团研究院联合发布的《2020中国家庭财富指数调研报告》②研究表明,受疫情影响,我国家庭对理财的重视程度日益提高,对金融资产的配置也更加重视,家庭金融已经成为了我国金融结构中一个不容忽视的构成因素。
...........................
1.2 国内外研究
1.2.1 客户识别的机器学习算法相关文献
在运用机器学习的方法对客户进行分类识别的研究领域,很多学者已经在不同的统计机器学习方法以及神经网络等方面运用各种不同的分类算法取得了不俗的成果。
在运用聚类分析方面,赵铭、李雪、李秀婷、吴迪(2013)[49]等人综合考虑客户信息、价值和行为三个维度的指标,采用K-means聚类方法结合判别分析法进行商业银行基金理财客户分类研究,研究表明该方法能有效地识别基金理财客户。罗彪、闫维维、万亮(2013)[31]等利用网络层次分析法(ANP)和K-means聚类算法,从客户当前价值和潜在价值两个维度对客户群进行细分。结果表明,该模型能够对客户价值进行全面、客观的评价和分类。
在运用支持向量机(SVM)方面,王波、郝艳友、刘勇奎、刘爽(2008)[38]等人的研究解决了支持向量机在房贷信用评估中的应用问题,证明了基于SVM的房贷信用评估方法效果很好,比银行原有的方法更加有效。
在运用决策树方面,张婷婷、贺昌政、肖进(2012)[47]等研究了不完整数据中的客户分类问题,提出了一种使用动态分类器集成选择的不完整数据分类方法,结果表明,与现有算法相比,使用该算法分类具有更高的准确率和稳定性,能够更有效地对客户进行分类。卢媛媛,、张剑、何海燕(2011)[30]等选取客户的基本信息和交易数据,采用决策树方法进行挖掘分析,使用WEKA算法对客户交易数据训练集进行训练、测试和验证,构建客户分类决策模型,对客户分类系统的分析和设计具有很大的参考意义。国外学者Young Moon Chae,Seung Hee Ho(2001)[17]等人在韩国的一个医学数据库中应用了机器学习技术,通过 Logistic回归和两种决策树方法对高血压患者进行了预测。杨彬、田甜(2011)[42]等对银行理财产品营销的关联规则进行挖掘,通过最小化挖掘出来的规则与测试数据间的差异来对客户理财能力进行划分,为银行有效地营销产品、增加收益、提高客户财富值提供了参考。
.............................
2 理论基础
2.1 金融资产、家庭资产与家庭金融资产
金融资产[53]是广义意义上的无形资产,他拥有对实物资产的索取权,能够给其持有者带来一定的货币收入。包括现金、储蓄存款、债券投资、股票投资、票据、保险等。此外金融资产可以直接在金融市场上进行交易,相比起一些实物资产,金融资产有更强的流动性。此外,与其他有形的实物资产不同,金融资产不一定具有固有的实物价值,它们的价值反映的是它们在交易市场的供求关系,以及其所承担的风险水平,会随着时间的变化而有所不同。
家庭资产主要分为非金融资产与金融资产两大类,家庭非金融资产大部分是一些有形实物资产,包括房产、汽车、耐用消费品、金银首饰以及其他的贵重物品。家庭金融资产是指以债权、权益等无实物存在形式的无形资产,例如现金、储蓄、股权股票、债券、保险、票据等金融产品与金融衍生品,家庭金融资产在家庭资产中占有重要地位。
.................................
2.3 决策树模型
2.3.1 决策树模型基本原理
决策树是一种由结点与有向边组成的树,这里的结点又分为叶结点和内部结点,内部结点代表着样本数据的一个属性或特征,而叶结点代表分类结果。图2.1是一个决策树示意图,小圆点表示决策树的内部结点,小方框表示决策树的叶结点。
投资分析论文怎么写
决策树模型是一种比较常用的分类算法模型,根据不同的数据集划分标准有不同的树,通常的划分标准有信息增益,信息增益率、基尼系数,根据信息增益,信息增益率、基尼系数这三种数据集的划分方法分别有决策树的ID3算法、C4.5算法以及CART算法,本文主要介绍和应用基于基尼系数的CART算法。
................................
3 数据来源、变量选择与数据预处理 ......................... 16
3.1 数据来源 ....................................... 16
3.1.1 中国综合社会调查(CGSS)数据库介绍 ......................... 16
3.1.2 中国综合社会调查(CGSS)问卷介绍 ........................... 16
4 我国参与中高风险金融资产投资的家庭识别 ................................ 24
4.1 分类模型类不平衡问题及其处理 .............................. 24
4.2 Logistic模型的建立与识别 .................................... 26
5 我国家庭参与中高风险金融资产投资影响因素分析 ....................... 36
5.1 随机森林变量重要性指标 ......................... 36
5.2 随机森林模型中各变量重要性情况 ................................ 36
5 我国家庭参与中高风险金融资产投资影响因素分析
5.1 随机森林变量重要性指标
根据前面对Bagging算法的介绍,我们知道在随机森林模型中,训练每一棵决策树的时候都会产生袋外数据(OOB)。通常在计算每棵决策树的预测误差时,能够利用其袋外数据,具体做法是对于某个特征X,先对其计算一次误差,然后对该特征随机地加入噪声干扰,加入噪声干扰后再计算一次误差,两次误差的变化就是该决策树中特征X的变量重要性,而随机森林模型中特征X的变量重要性则是模型中全部决策树特征X变量重要性的平均值,若这个值大说明这个特征对样本分类结果的影响很大,说明该属性特征的重要性就比较大。因此,在采用随机森林算法时,根据各特征的变量重要性程度,可以对各属性的重要程度进行排序。
由以上章节可知在实证的几个模型之中,Logistic模型与随机森林模型的分类效果是比较好的,所以,运用这两种模式对我国家庭参与中高风险金融资产的影响因素进行分析是较为合理的,本章运用Logistic回归系数和随机森林模型的变量重要性指数,对我国家庭参与中高风险金融资产的影响进行探讨。
投资分析论文参考
......................................
6 结论与建议
6.1 结论
在我国参与中高风险金融资产投资的家庭的识别方面,对比三个模型发现Logistic回归模型正例的查全率和查准率分别为0.87和0.81,AUC指标达到0.90,随机森林模型正例的查全率和查准率分别为0.88和0.79,AUC指标也达到了0.89,而决策树模型的效果则比较差,正例的查全率和查准率分别为0.77和0.73,其AUC指标也仅仅达到0.80,Logistic回归模型与随机森林模型相比起决策树模型有更好的性能以及更高的准确率。
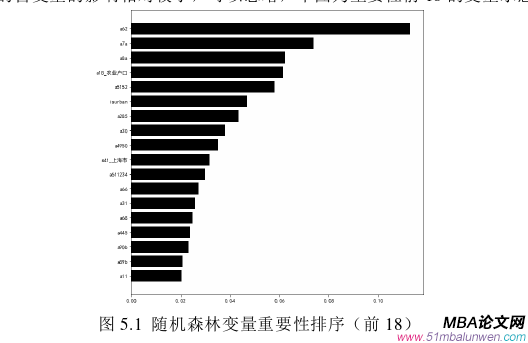
同时,本文还发现了影响我国家庭参与风险金融资产投资的主要因素,并进行了相应的实证分析。表5.1表明,在所有自变量中,最重要的18个自变量的重要性之和达到75.92%,从地域上来看,上海市、北京市、广东省、浙江省4个经济比较发达的省份的变量重要性占据了地域重要性排名的前四位,说明经济发达地区省份的家庭普遍要比经济比较不发达地区的省份的家庭对于中高风险金融资产投资的意愿要高,从户口性质上看可以发现持农村户口的家庭对比持城市居民户口的家庭有更低的中高风险金融资产投资意愿,说明农村地区家庭普遍都是风险厌恶,除地域与户口因素外,一个家庭是否参与中高风险金融资产投资的原因还有社会、家庭、个人三个维度的原因::
(1)在个人因素方面,变量a7a(最高受教育程度)、a8a(个人年收入)、a5152(英语水平)、a30(是否使用网络支付)、a4950(普通话水平)、a31(年龄)重要性程度排在前列,这其中最高受教育程度、个人年收入、普通话水平以及英语水平这几个因素较为重要。
(2)在家庭因素方面,变量a62(全家家庭总收入(2016年))、isurban(所在地是否为城市)、a66(家庭是否拥有家用汽车)、a68(子女数量)、a90b(母亲最高受教育程度)、a89b(父亲最高受教育程度)、a11(住房面积)重要性程度排在前列,这其中全家家庭总收入以及所在地是否为城市两个因素较为重要。
(3)在社会因素方面,变量a285(互联网使用程度)、a611234(对社会保障项目的重视程度)、a445(政治参与积极程度)重要性程度排在前列,这其中最重要的是互联网使用程度。
参考文献(略)
- 中国人寿保险(集团)公司股权投资案例分析2020-03-15
- JA公司养老服务中心项目投资效益分析2020-04-20
- 中部四省宏观经济波动比较投资分析 --基于SVAR模型2020-06-25
- CH集团公司社会影响力投资分析研究2020-07-26
- 毅雷私募基金公司风控管理策略的优化研究2020-09-27
- 环境不确定性、客户集中度与银行贷款成本—基于我...2020-10-03
- A公司投资效率的提升对策研究2020-10-09
- 浮梁通用机场项目投资分析2021-02-03
- 芦淞国投AA房地产项目投资分析研究2021-02-05
- 通发公司零部件加工中心建设项目投资分析2021-02-07

